
深度学习
7、tf 分布式训练
https://blog.csdn.net/hjimce/article/details/61197190
6、卷积池化层
Global Average Pooling GAP全局池化
https://blog.csdn.net/Touch_Dream/article/details/79775786
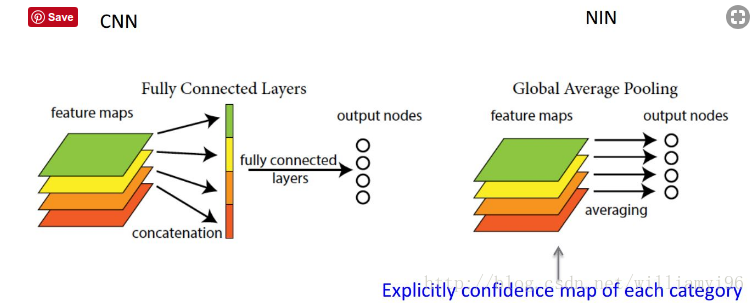
由此就可以比较直观地说明了。这两者合二为一的过程我们可以探索到GAP的真正意义是:对整个网路在结构上做正则化防止过拟合。其直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的类别意义。做法是在最后卷积层输出多少类别就多少map,然后直接分别对map进行平均值计算得到结果最后用softmax进行分类。
With Global pooling reduces the dimensionality from 3D to 1D. Therefore Global pooling outputs 1 response for every feature map. This can be the maximum or the average or whatever other pooling operation you use.
It is often used at the end of the backend of a convolutional neural network to get a shape that works with dense layers. Therefore no flatten has to be applied.
5、keras深度学习组件包 博客
https://codekansas.github.io
1、MLP
输入:
Continuous -> values
Sparse – >(embeddings)
输出:
Continuous – linear
Sparse – softmax
2、多层感知器
相当于通过局部拟合实现的非线性。
见:oxford-cs-deepnlp-2017-lectures Lecture 1b – Deep Neural Networks Are Our Friends.pdf P103-p200
3、
Embedding Pretraining
4、计算强度衡量
Computational intensity 计算强度。
Arithmetic Intensity 算力
Computational intensity is defined as the number of floating point operations per byte: Flops/Byte=
Roofline Model 提出了使用 Operational Intensity(计算强度)进行定量分析的方法
https://zhuanlan.zhihu.com/p/34204282?edition=yidianzixun&utm_source=yidianzixun&yidian_docid=0ITDcElz
5、深度学习参数初始化
如果隐藏层参数初始化为相同值,且输出层只有一层。会造成,每个隐藏层节点值都是一样的,且更新是一样的。
那么线性回归或softmax回归是否可以初始化为相同值呢? 可以的。
微信扫一扫,分享到朋友圈

