
有一个词库里面包含d个词,词的最大字符长度为m,判断一篇文章中是否包含有词库中的词,文章最大长度为n,判断是否即可。
我曾经面试被问到这个问题,我觉得我的想法还不错,效率应该是n*m,应用kmp的思想应该还可以提高,今天就把这个问题写一下。
方法一:
利用子串查找的方法,遍历每一个词,进行判断。子串查找有一个高效的算法kmp,回头补进来代码,今天先写我想到的办法。 kmp复杂度问 n+m, 那么整体复杂度为 d*(n+m)
方法二:
按字构造词库,简历hash树结构。比如: 中国,中华,中国人 ,政府 即为:
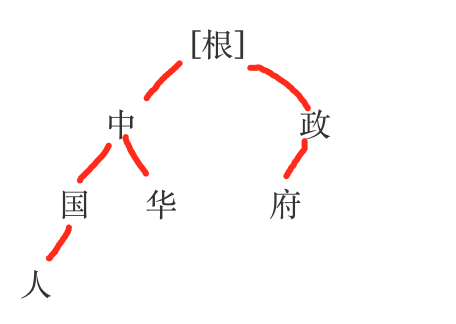
从根往下,即可存储所有的词,每一层使用hash映射,在结尾的字上打个标识,告诉这是一个完整词的结尾。从根部与文章第一个字匹配,匹配成功继续往下匹配。直到不成功,匹配的位置向后移动。
该算法复杂度为 m*n 与d无关。 是否可以向kmp一样跳跃式往后移动,我目前还不清楚。
下面看一下算法:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 |
import time from kmp import kmp def read_file(path): with open(path) as fr: return fr.read().strip().split('\n') class Node(object): def __init__(self, is_leaf=False, is_end=False): self.is_leaf = is_leaf self.is_end = is_end self.next = {} def build_tree(words): tree = {} for word in words: ws = list(word) length = len(ws) current = tree for idx, w in enumerate(ws): if w not in current: current[w] = { 'is_leaf': False, 'next': {} } # 是一个词的结尾 if idx == length-1: current[w]['is_leaf'] = True current = current[w]['next'] return tree def match_doc(tree, doc_str): char_list = list(doc_str) doc_length = len(char_list) doc_pos = 0 match_word = "" current = tree # 记录当字需匹配的字典 match_length = 0 while True: if doc_pos + match_length >= doc_length: return "" char = char_list[doc_pos + match_length] if char in current: match_word += char next = current[char]['next'] if current[char]['is_leaf']: # 当前字为词的结尾,则匹配成功,返回 return match_word if len(next) == 0: # 到叶子节点,未匹配成功,则向下走一位 match_length = 0 match_word = "" doc_pos += 1 current = tree if not current[char]['is_leaf'] and len(next) > 0: # 向后移动 match_length += 1 current = next else: # 如果未能匹配成功,向后移动一位 match_word = "" doc_pos += 1 current = tree match_length = 0 if __name__ == "__main__": words = read_file('words.txt') n = -1 build_tree(words[:n]) tree = build_tree(words[:n]) lines = read_file('1984.txt') start = time.time() for line in lines: match_w = match_doc(tree, line) if match_w != "": print("{} \t {}\n".format(match_w, line)) end = time.time() print(end-start) # 0.10075116157531738 # 测试kmp start = time.time() for line in lines: for word in words: result = kmp(line, word)import time from kmp import kmp def read_file(path): with open(path) as fr: return fr.read().strip().split('\n') class Node(object): def __init__(self, is_leaf=False, is_end=False): self.is_leaf = is_leaf self.is_end = is_end self.next = {} def build_tree(words): tree = {} for word in words: ws = list(word) length = len(ws) current = tree for idx, w in enumerate(ws): if w not in current: current[w] = { 'is_leaf': False, 'next': {} } # 是一个词的结尾 if idx == length-1: current[w]['is_leaf'] = True current = current[w]['next'] return tree def match_doc(tree, doc_str): char_list = list(doc_str) doc_length = len(char_list) doc_pos = 0 match_word = "" current = tree # 记录当字需匹配的字典 match_length = 0 while True: if doc_pos + match_length >= doc_length: return "" char = char_list[doc_pos + match_length] if char in current: match_word += char next = current[char]['next'] if current[char]['is_leaf']: # 当前字为词的结尾,则匹配成功,返回 return match_word if len(next) == 0: # 到叶子节点,未匹配成功,则向下走一位 match_length = 0 match_word = "" doc_pos += 1 current = tree if not current[char]['is_leaf'] and len(next) > 0: # 向后移动 match_length += 1 current = next else: # 如果未能匹配成功,向后移动一位 match_word = "" doc_pos += 1 current = tree match_length = 0 def pmt(s): """ PartialMatchTable """ prefix = [s[:i+1] for i in range(len(s)-1)] postfix = [s[i+1:] for i in range(len(s)-1)] intersection = list(set(prefix) & set(postfix)) if intersection: return len(intersection[0]) return 0 def kmp(big, small): i = 0 while i < len(big) - len(small) + 1: match = True for j in range(len(small)): if big[i+j] != small[j]: match = False break if match: return True #移动位数 = 已匹配的字符数 – 对应的部分匹配值 if j: i += j - pmt(small[:j]) else: i += 1 return False if __name__ == "__main__": words = read_file('words.txt') n = -1 build_tree(words[:n]) tree = build_tree(words[:n]) lines = read_file('1984.txt') start = time.time() for line in lines: match_w = match_doc(tree, line) if match_w != "": print("{} \t {}\n".format(match_w, line)) end = time.time() print(end-start) # 0.10075116157531738 # 测试kmp start = time.time() for line in lines: for word in words: result = kmp(line, word) if result: print(word) end = time.time() print(end - start) # > 30min 我等了8分钟才找出100个, 上个算法找出了400多个,不能再等了。 |
所以,这次kmp也慢了。
未来: 如果再提供一个信息,文章数量为k,是否也可以从文章做工作。再议。
转载文章,版权归作者所有,转载请联系作者。作者:,来源:
喜欢
(0)

微信扫一扫,分享到朋友圈
