
关键词:python, scrapy, selenium, css伪类
最近准备做车评方面的数据分析工作,计划使用汽车之家口碑中的数据。
当我开始用我传统的方法scrapy去爬取时发现,汽车之家对文字内容作了一定的反爬处理。把大段的文本内容,抽出一部分高频的关键词,通过css伪类的方式进行展示。比如“满意”是其中一个词,通过看html源码,如“最满意的一点”却是:“最<span class=”hs_kw0_mainpl”></span>的一点”。那么如果简单的通过获取html内容就只能得到:最的一点。如果文章中的许多高频词都不能获取到,那文章也是没有意义的了。
如下:<span class=”hs_kw0_mainpl”></span> 的所表达的内容是由伪类定义的,::before content:满意 。
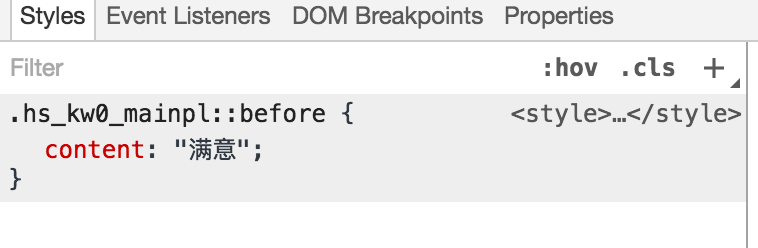
我最直接的想法是,从源代码中找到定义class=”hs_kw0_mainpl”的css文件,然后通过解析规范后,把<span class=”hs_kw0_mainpl”></span>还原成原始的内容。但是找了一段时间也没找着。而在分析的过程中,发现即使是相同一个词,比如“满意”,其class并不是一成不变一直是hs_kw0_mainpl的。一段时间后可能又变成了另外一个class,但类似于这种格式的class名。
既然相同的词class也会改变,那么肯定是动态生成的css文件了。那么做出class到对应文字的映射是没有意义的。
继续尝试。
通过google搜索,发现,是可以通过js获取到伪类的属性值的。
如下代码:
|
1 2 |
getComputedStyle(document.getElementsByClassName('hs_kw0_mainmX')[0],'before') .getPropertyValue('content') |
那么现在思路就清晰了。通过浏览器访问,并执行js代码,获取到该span的伪类设置的值,再进行文字的替换。
模拟浏览器我使用的是selenium工具,总体感觉比较方便。
期间遇到的问题:
1、通过selenium打开chrome浏览器去访问网页,正常我这边速度大概一秒爬一个地址,但总有一定的概率,1/5000左右,网页不动了,第一次跑的时候,开了8个进程同时跑,一秒一页的话,预计第二天应该能有30w左右数据,第二天来了发现,才十万,而打开的7个浏览器都不动了,而任务却没有进行完。
大概原因是selenium等待网页加载完毕后继续执行,虽然网页已经显示出了内容,但可能有一些因素导致一直无法触发browser.get()加载完毕的条件。
|
1 2 |
browser = webdriver.Chrome() browser.get(response.url) |
解决方法:
首先:设置超时时间: browser.set_page_load_timeout(15)
|
1 2 3 4 5 6 |
try: self.browser.get(response.url) except TimeoutException: #重启bower self.browser.quit() self.chrome_init() |
当遇到超时异常时,重启浏览器。可以解决。
2、因为目前计划只需要爬去网页的内容,所以图片和其他不必要的东西就不要加载了,以节省资源。
我开始搜索如何设置,禁用flash和图片加载。有不少地方讲到。而参数设置,我并没在selenium文档中找到具体Chrome浏览器设置的介绍。
于是开始各种尝试,对启动浏览器时进行设置参数。
最终有效的设置结果是:
|
1 2 3 4 |
chrome_options = webdriver.ChromeOptions() prefs = {"profile.managed_default_content_settings.images": 2,"plugins.plugins_disabled": ["Shockwave Flash"] } chrome_options.add_experimental_option("prefs", prefs) self.browser = webdriver.Chrome(chrome_options=chrome_options) |
网上有不少设置方式,在我这里却没有生效,以上是尝试了许多种方法中,最终有效的方法。
对于这次汽车之家口碑数据的爬取,大概就这些吧。截止到2017年3月初,大概83w条口碑数据。最终爬下来未压缩的文字数据:1.5G。这还不包括追加的口碑和评论。主要是下图中的内容:
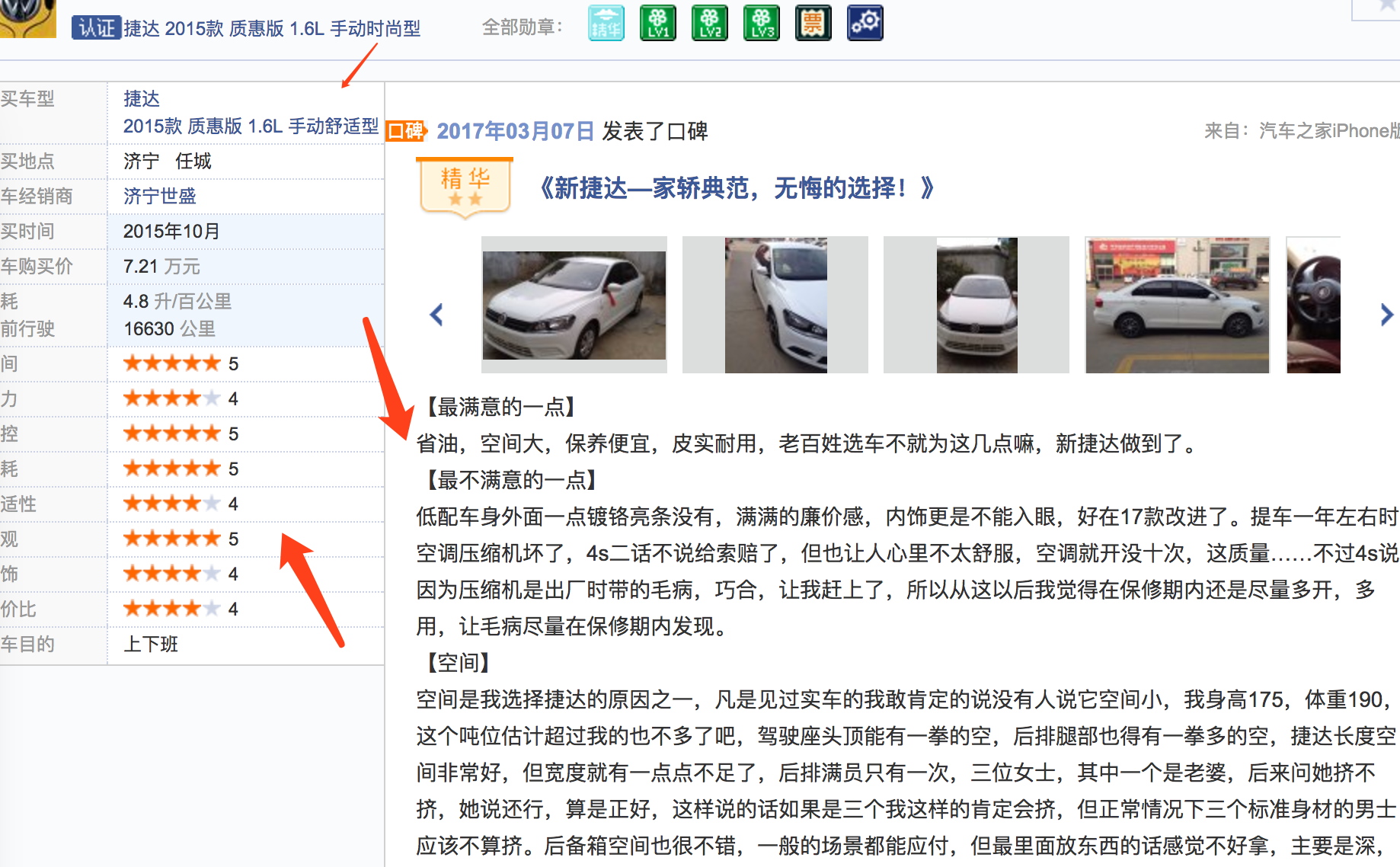
期望我走过的坑,能帮到后来的人。
我把爬取的数据分享到百度网盘了,压缩后500M,如对自然语言感兴趣的,可以直接拿去研究。
链接: https://pan.baidu.com/s/1hrNMkdA 密码: tux3
=====2017.8.12 更新=====
github地址: https://github.com/keepangry/autohome_koubei_crawler.git
=====end=====
格式如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
爬取文本内容样例: id,"content","created_at","url",series_id,"series_name",spec_id,"spec_name","address","buy_date","buy_price",space,power,manipulation,fuel,comfort,surface,trim,ratio,"purpose","title","date" 8,"2016年12月07日发表了口碑口碑《完美小钢炮,动力十足》【最满意的一点】动力十,操控稳定极好...","2017-03-06 12:07:13","http://k.autohome.com.cn/spec/25904/view_1389721_1.html?st=23&piap=0|3170|0|0|1|0|0|0|0|0|1",3170,"奥迪A3",25904,"奥迪A32016款 Limousine 35 TFSI 领英型","成都","2016年5月","19.30万元",3,5,4,4,3,5,4,4,"自驾游泡妞","完美小钢炮,动力十足","2016年12月07日" 7,"2016年12月08日发表了口碑口碑《漂亮 精致 唯美》【最满意的一点】1、A3获过内饰5、售后...","2017-03-06 12:07:13","http://k.autohome.com.cn/spec/25905/view_1391269_1.html?st=22&piap=0|3170|0|0|1|0|0|0|0|0|1",3170,"奥迪A3",25905,"奥迪A32016款 Limousine 35 TFSI 风尚型","天津","2016年9月","20.00万元",4,5,5,4,5,5,5,4,"上下班购物自驾游泡妞","漂亮 精致 唯美","2016年12月08日" '购买车型': 'spec_name', '购买地点': 'address', '购买时间': 'buy_date', '裸车购买价': 'buy_price', '空间': 'space', '动力': 'power', '操控': 'manipulation', '油耗': 'fuel', '舒适性': 'comfort', '外观': 'surface', '内饰': 'trim', '性价比': 'ratio', '购车目的': 'purpose', |
转载文章,版权归作者所有,转载请联系作者。作者:,来源:
微信扫一扫,分享到朋友圈


测试
抓取脚本分享一下呗?
嗯。
666
估计得等一段时间了,现在在上海出差,代码在北京电脑上,回头弄到github上。
好的 ,谢谢
已经传到git上了,地址在博文中,懒得改成可运行了,但之前是可运行的。如果需要,你参考看看吧。
666