
deeplearning tricks
4、优化方法
https://blog.csdn.net/u012328159/article/details/80311892
https://blog.csdn.net/willduan1/article/details/78070086
Momentum动量,一般使用前一次的0.9加上当前梯度的0.1。这样使梯度值更加稳定,减少震荡,更稳定的收敛。
缺点,引入了新的超参。
区别: SGD每次都会在当前位置上沿着负梯度方向更新(下降,沿着正梯度则为上升),并不考虑之前的方向梯度大小等等。而动量(moment)通过引入一个新的变量 vv 去积累之前的梯度(通过指数衰减平均得到),得到加速学习过程的目的。
最直观的理解就是,若当前的梯度方向与累积的历史梯度方向一致,则当前的梯度会被加强,从而这一步下降的幅度更大。若当前的梯度方向与累积的梯度方向不一致,则会减弱当前下降的梯度幅度。
AdaGrad
我们在每一次更新参数时,对于所有的参数使用相同的学习率。而AdaGrad算法的思想是:每一次更新参数时(一次迭代),不同的参数使用不同的学习率。
α* 梯度/sqrt(累积平方梯度)
RMSProp root mean square.
与AdaGrad相比,改变梯度积累为指数加权的移动平均
更新方式: α* 梯度/sqrt(加权累积平方梯度)
Adam
RMSProb使用梯度除以 sqrt(加权累积平方梯度)。二阶矩是加权,一阶未加权。
Adam使用 一阶矩的加权平均 / 二阶矩的加权。
一阶矩与二阶矩的加权参数不一样。一阶0.9,二阶0.999。
中间还会进行一次修正:除以1-β的t次方。
3、Batch Normalization layer
https://www.cnblogs.com/makefile/p/batch-norm.html?utm_source=debugrun&utm_medium=referral
我的总结:
1、covariate shift
经过多层网络,x值会发生偏移。
2、BN位置:激活函数之前。 即 y_bn = wx + b。 y = active(y_bn)
所以节点参数学习的就不是原x,而是x^。
3、BN进行了两次简化,1:不考虑变量间关系,只对单维度进行normalize。并没有进行去相关性的工作。 2:最合理的方式是全训练集normalize但是计算不允许,
所以进行batch内优化。并把γ、β作为学习的参数。
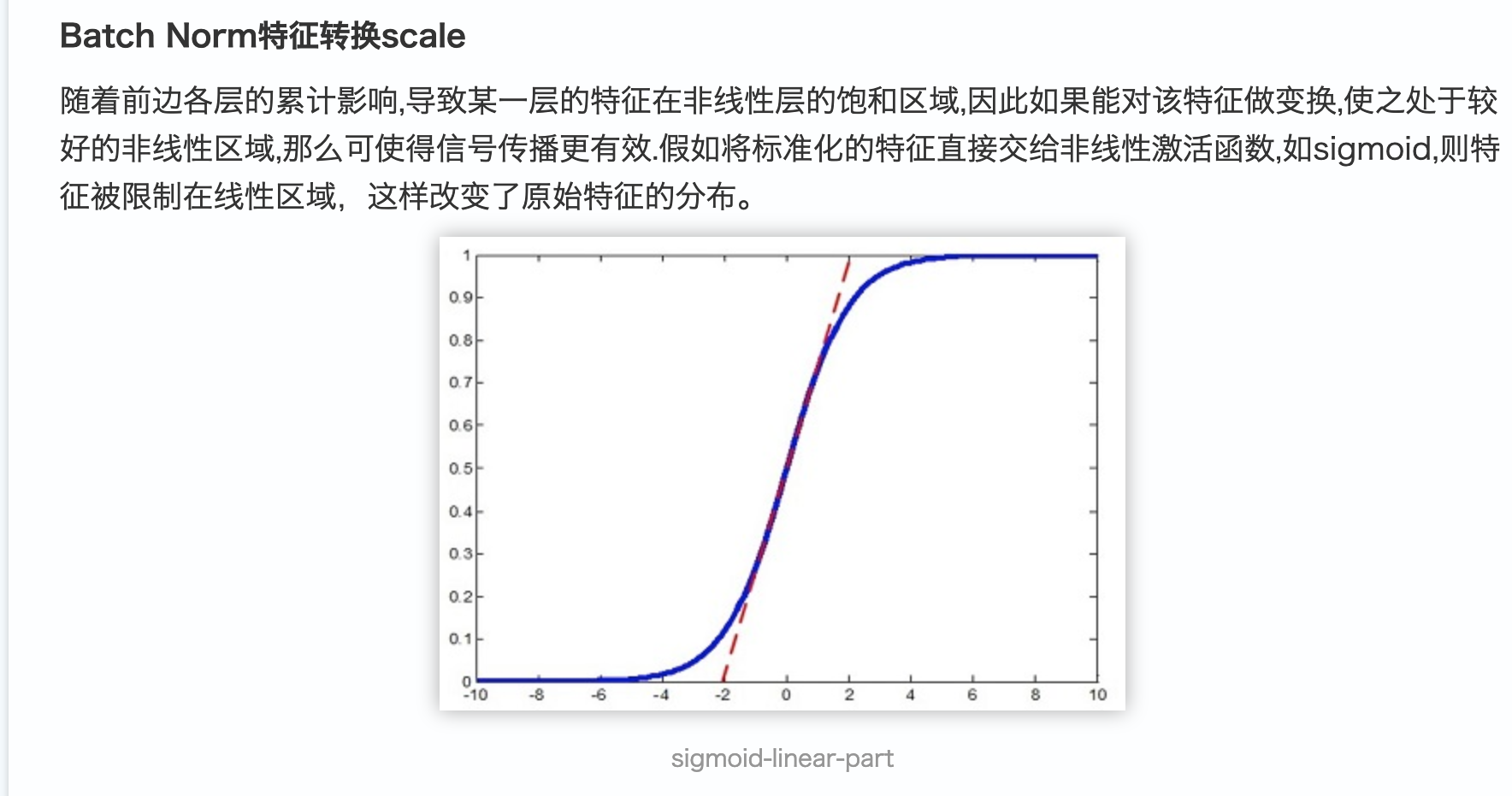
4、对于未进行BN前,数据进行优化时,无法保持在线性区间,比如sigmod在输入值较大时,梯度非常小。进行BN后,则可以使数据保持在均值0和单位方差之间。y
优点:
1、加速训练
2、对超参如 初始化与学习率不那么敏感
3、有一定的防止过拟合能力。
1、cnn下 K-Max均值采样技术(K-Max Average Pooling,KMA)
最大值采样 (max pooling) 和均值采样 (average pooling)。
K-Max采样技术选取其中最大的前K个值,并取其平均值作为最终的采样结果。K-Max均值采样的好处,一方面可以减少异常噪音点的影响,另一方面可以保留表现比较强的特征的强度。
来源方法: LSF-SCNN
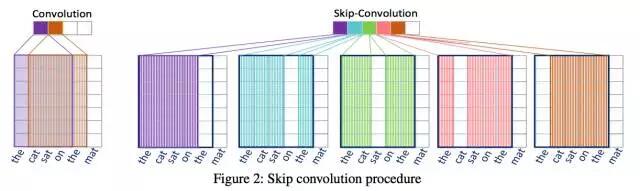
2、跳跃卷积技术(Skip Convolution,SC)
the cat sat on the mat
- 传统卷积方式将取得如下短语特征:{the cat sat on, cat sat on the, sat on the mat}
- 跳跃卷积将取得如下短语特征{the cat sat on, the cat sat the, the cat on the, the sat on the, cat sat on the, cat sat on mat, cat sat the mat, cat on the mat, sat on the mat }。
每次移动窗口中的一列,而不是整个窗口。
[1,2,3,4,5] 窗口为3,步长为1。
则为:[1,2,3] [1,2,4] [1,3,4] [2,3,4] [2,3,5] [2,4,5] [3,4,5]
来源方法: LSF-SCNN
微信扫一扫,分享到朋友圈

